


:quality(80)/p7i.vogel.de/wcms/35/e2/35e2b141e34ba3d45d19e97bb30e8502/0132382297v2.jpeg "Der Praxistag HPLC bringt Anwender zum Thema Flüssigchromatographie zusammen (Aufnahme vom Praxistag HPLC 2025). (Bild: VCG)")
:quality(80)/p7i.vogel.de/wcms/f4/9b/f49b99a6e8b33adac33a2fd63d15530a/0132188748v2.jpeg "Cryo-LA-ICP-TOFMS Setup am Alfred-Wegener-Institut (Bild: Alfred-Wegener-Institut / Pascal Bohleber)")
:quality(80)/p7i.vogel.de/wcms/38/0f/380f838661d049cee2dd095310629084/0131604580v2.jpeg "Die Exsikkator sind in drei verschiedenen Größen erhältlich, von ca. 50 bis 300 Liter Innenraumvolumen. (Bild: Sicco)")
:quality(80)/p7i.vogel.de/wcms/9f/62/9f624b2708be7126e559f374767fe4c8/0132084408v2.jpeg "Der Technotrans-Peltier-Kühler liefert eine Temperaturstabilität von ±0,05 Kelvin, schnelle Reaktionszeiten und ist mit unterschiedlichen Medien kompatibel. (Bild: technotrans SE)")
:quality(80)/p7i.vogel.de/wcms/d3/83/d3839fc5d7d5590eead5fd606c6479b5/0132374775v2.jpeg "Krümel und Brotreste haben schon unsere Großeltern für Paniermehl und Semmelklöße weiterverwendet. Was früher selbstverständlich war, heißt heute „Upcycled Ingredients“ und fasst in der Lebensmittelindustrie zunehmend Fuß. So wird Lebensmittelverschwendung reduziert. (Symbolbild) (Bild: frei lizenziert, Delfina Cocciardi)")
:quality(80)/p7i.vogel.de/wcms/c9/22/c9229cc360d30a8dce68bf4a6fc6bd98/0131564364v2.jpeg "Taschen-pH-Meter Five Go F2 (Bild: Carl Roth)")
:quality(80)/p7i.vogel.de/wcms/ed/cf/edcf0d95b0d71585dfcbd0676add3f72/0132026051v2.jpeg "Abb.1: Die mobile Phase bei HILIC hat ein paar Besonderheiten. Dieser Tipp erklärt, wie die besten und schnellsten Ergebnisse zu erzielen sind und was es bei der Methodenentwicklung zu beachten gilt. (Bild: VCG – Lüttmann)")
:quality(80)/p7i.vogel.de/wcms/07/2e/072eea36c2f90886bf44c36daeff17a6/adobestock-413347368--c2-a9-20airborne77-20-e2-80-93-20stock-adobe-com-4242x2385v1.jpeg "Die bisher vorherrschende Annahme lautete: Je vielfältiger die verfügbaren Nährstoffe sind, desto mehr Arten können nebeneinander leben. Für Mikrobiome, so auch für das Darmmikrobiom, könnte dies jedoch nicht zutreffen. (Symbolbild) (Bild: Adobe Stock / airborne77)")
:quality(80)/p7i.vogel.de/wcms/6c/9b/6c9b2cf5eacf70b658e2e3fff3cd0a6a/0132401567v2.jpeg "Olivia Merkel, Professorin für Drug Delivery im Department Pharmazie der LMU, erhielt 150.000 Euro vom Europäischen Forschungsrat für ihre Forschung zu neuartigen RNA-Nanocarriern. (Symbolbild) (Bild: Erwin Bosman / Pixabay)")
:quality(80)/p7i.vogel.de/wcms/01/48/0148516bae800e454da27a827b186181/0132389668v1.jpeg "Ob warm oder kalt: Nur eine Gruppe von Nervenzellen der Haut nimmt Temperaturreize wahr. (Symbolbild) (Bild: GPT Image Editor / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/99/c4/99c43e588512cca2823bf419ed536e98/0132315534v2.jpeg "Workshop am Helmholtz-Zentrum für Umweltforschung (UFZ) zum Thema neuartige Substanzen und deren Regulierung (Bild: @Bastian Worrmann/www.youtube.com/watch?v=6Dcv8yWaHtU)")
:quality(80)/p7i.vogel.de/wcms/52/08/52085a521e97dcabba1f99d2aa76cb5a/0132308084v2.jpeg "Ultrafeinstaub besteht aus so kleinen Partikeln, dass diese von der Lunge ins Blut und sogar bis ins Gehirn vordringen können. Besonders in Großstädten ist die Konzentration solcher Partikel in der Luft bedenklich hoch (Symbolbild). (Bild: © Tommy - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/ce/c2/cec2742ba143cf13f1d6611bf852c584/0132256688v2.jpeg "Verschiedene Weizensorten auf einem Versuchsfeld. (Bild: Borjana Arsova (IBG-2))")
Graphtechnologie in der medizinischen Forschung Vernetzt gegen Diabetes: Wie Big Data harmonisieren?
Die Harmonisierung von Big Data ist in vielen Forschungsbereichen derzeit ein großes Thema. Um die riesigen und heterogenen Datenmengen aus der medizinischen Forschung standortübergreifend und effizienter zu nutzen, setzt das Deutsche Zentrum für Diabetesforschung (DZD) für sein Daten- und Knowledge-Management auf eine Graphdatenbank. Wie die Forschung an der Volkskrankheit Diabetes davon direkt profitiert, lesen Sie hier.
Anbieter zum Thema
:fill(fff,0)/images.vogel.de/vogelonline/companyimg/15200/15260/65.jpg "t&p_Logo10_1.jpg ()")
Rund 6,7 Millionen Menschen in Deutschland leiden unter Diabetes – davon etwa 90% unter der nicht genetisch bedingten Form Diabetes mellitus (Typ 2). Damit gehört Diabetes zu den bedeutendsten Volkskrankheiten in Deutschland und in anderen Industrienationen. Um neue Methoden zur Prävention und Behandlung von Diabetes zu entwickeln, wurde im Jahr 2009 das Deutsche Zentrum für Diabetesforschung (DZD) vom Bundesministerium für Bildung und Forschung (BMBF) gegründet. Dieser Forschungsverbund bündelt auf nationaler Ebene Experten aus Universitätskliniken und Forschungseinrichtungen, um disziplinübergreifend und mithilfe modernster biomedizinischer Technologien, Erkenntnisse zur Entstehung, zum Verlauf und zu Behandlungsmöglichkeiten von Diabetes zu gewinnen.
Harmonisierung heterogener Daten aus der Diabetesforschung
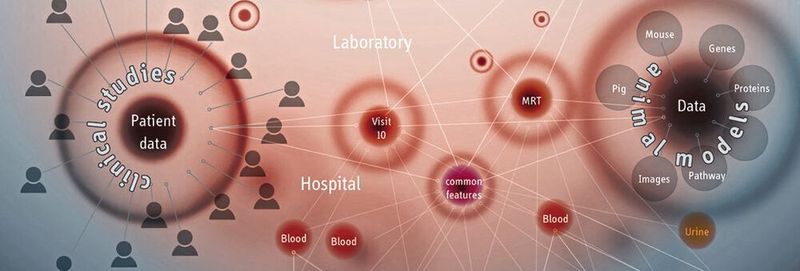
Die Harmonisierung von Big Data ist in vielen Forschungsbereichen heutzutage ein großes Thema – insbesondere in der medizinischen Forschung. Das DZD verfügt über eine riesige Anzahl heterogener Daten, die über die verschiedenen Standorte deutschlandweit verteilt sind. Dazu gehören neben Daten und Informationen aus der Grundlagenforschung auch klinische Studien, Berichte, Umfragen, Fachliteratur, Patientenproben und internationale Forschungsprojekte. Zusätzlich angereichert wird dieser Datenberg durch moderne, disziplinübergreifende Forschungsmethoden, die fortlaufend neue Daten generieren. Denn es ist schon lange unzureichend, Krankheitsursachen nur von einer Perspektive aus zu beleuchten. So verknüpfen die Wissenschaftler des DZD beispielsweise molekulare Humandaten aus der Grundlagenforschung mit Daten aus Tiermodellen, um neue Erkenntnisse zu gewinnen.
Um von diesem heterogenen Datenberg eine holistische Ansicht der Informationen zu erhalten, baut das Deutsche Zentrum für Diabetesforschung eine übergeordnete Datenbank auf. Das zentrale Daten- und Knowledge-Management verfolgt das Ziel, den 400 beteiligten Wissenschaftlern standort-, disziplin-, spezies- und datenübergreifend Zugriff auf alle relevanten Information zu ermöglichen und die Daten in einen Kontext zu bringen.
Als die Bioinformatiker des DZD ein Konzept für die zentrale Datenbank entwickelten, ging es nicht allein um eine Datenbank zur Datenspeicherung, sondern auch um die Möglichkeit, die Beziehungen zwischen den Daten zu nutzen. Diese Anforderungen erfüllt die Graphdatenbank Neo4j. Im Gegensatz zu relationalen Datenbanken liegt die Stärke bei Graphdatenbanken darin, Datensätze und ihre Beziehungen untereinander in Echtzeit abzufragen. Dabei sind die Vorteile die Geschwindigkeit und die einfache Modellierung der Daten. Ein Graph besteht dabei aus Knoten (z.B. Patient, Bio-Sample, Studie) und Kanten (z.B. „enthält“, „untersucht“, „misst“). Beiden kann eine beliebige Anzahl qualitativer und quantitativer Eigenschaften zugewiesen werden, beispielsweise Messparameter und Werte.
:quality(80)/images.vogel.de/vogelonline/bdb/1498300/1498342/original.jpg "(DZD)")
:quality(80)/images.vogel.de/vogelonline/bdb/1498300/1498330/original.jpg "(DZD)")
:quality(80)/images.vogel.de/vogelonline/bdb/1498300/1498331/original.jpg "(DZD)")
:quality(80)/images.vogel.de/vogelonline/bdb/1498300/1498332/original.jpg "(Das DZD ermöglicht Diabetes aus mehreren Blickwinkeln zu erforschen (Quelle DZD))")
Gemeinsames Forschen – ein Informationskontext
Auf Grundlage der Graphdatenbank Neo4j entwickelten die DZD-Bioinformatiker die Graphdatenbank namens DZD connect. Diese liegt als Zwischenschicht über den relationalen Datenbanken und greift auf bestehende Systeme und Datensilos im DZD zu. Für einen zentralen Zugriff auf alle Informationen im DZD war im ersten Schritt eine einheitliche Datengrundlage nötig. Die Metadaten mussten standardisiert, normalisiert und in das Graphmodell integriert werden. Nur so können die Messergebnisse und Daten verglichen und Lücken und Redundanzen vermieden werden.
Im Graphen selbst entsteht schnell ein reichhaltiger Kontext an Informationen, der den Datenverbindungen einen besonderen Stellenwert einräumt. Forscher können in Echtzeit Informationen wie Messwerte, Langzeitstudien von Diabeteserkrankten oder Tiermodelldaten abrufen. Weitere Vorteile dieser Technologie sind die Skalierbarkeit des Systems und die Möglichkeit, Daten jederzeit zu ergänzen. Informationen zu neuen Studien, Fachliteratur, Patienten oder neuen Forschungsergebnissen lassen sich schnell und einfach hinzufügen und aktualisieren.
(ID:45580078)
:quality(80)/p7i.vogel.de/wcms/03/1e/031e4c91af9d4d09d3ab10b9d490c738/0129957843v2.jpeg "Abb.1: Daten-Dirigent im Labor – Ein Messplatz bestehend aus DMA 5002, Abbemat 5101 und Xsample 5200 mit externer Ansteuerung durch AP Connect zur Übermittlung der Probenliste und automatischer Übertragung der Messdaten. (Bild: Anton Paar GmbH (Hintergrund: Dall-E / KI-generiert))")
:quality(80)/p7i.vogel.de/wcms/ea/a8/eaa8dbf8c71f492ff7029d0e4adde44a/0126997090v1.jpeg "Immer mehr Studien deuten darauf hin, dass zuckerhaltige Getränke nicht nur - wie bekannt - die metabolische, sondern auch die psychische Gesundheit beeinträchtigen. (Symbolbild) (Bild: © Markus Mainka - stock.adobe.com)")